Generating Raw Sequencing Reads
The generation of raw sequencing reads serves as an essential foundation in genomics and bioinformatics research. It involves the process of converting DNA or RNA from a biological sample into a digital format for subsequent analysis. The unprocessed sequencing reads serve as the basis for nearly all future analyses, including genome assembly, variation identification, and gene expression investigations. High-throughput sequencing technologies have revolutionized the field by allowing for the rapid and cost-effective generation of massive amounts of sequencing data. These raw reads contain valuable information about the genetic makeup of an organism, providing researchers with a wealth of data to explore and analyze.
1. Sample Preparation: DNA/RNA Extraction
The process starts with sample preparation, during which DNA or RNA is extracted from a biological source, such as blood, tissue, or cells. The quality of the extracted material is paramount, as damaged or contaminated samples can result in suboptimal sequencing outputs.
-
DNA Extraction: High-quality genomic DNA is obtained for genomic investigations utilizing various techniques and kits specifically developed for purifying DNA from biological materials.
-
RNA Extraction: In transcriptomics or RNA sequencing (RNA-seq), RNA is isolated from the sample. Maintaining RNA integrity is essential due to its greater susceptibility to degradation compared to DNA.
Upon purification, the nucleic acids undergo quality assessments to verify their concentration and purity prior to advancing to subsequent processes.
2. Library Preparation
The initial phase of the sequencing process is library preparation, which generally encompasses the following steps:
-
Fragmentation: The isolated DNA is too large for direct sequencing, so it is cleaved into smaller fragments using mechanical (e.g., sonication) or enzymatic methods.
-
Adapter Ligation: Short, synthetic DNA sequences known as adapters are ligated to the termini of each DNA fragment. These adapters comprise sequences recognized by the sequencing platform.
-
Barcode Addition: Distinct barcodes (short DNA sequences) are incorporated to differentiate samples during the pooling of many specimens in a single run (multiplexing).
-
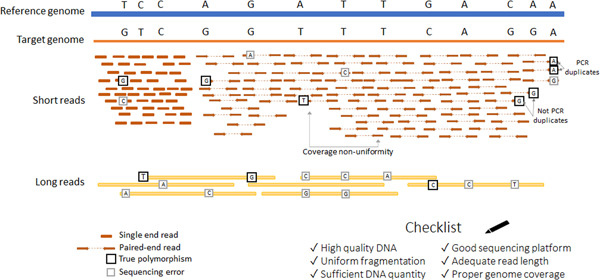
Amplification (Optional): In instances of insufficient DNA quantities, the fragments may be amplified via PCR to guarantee adequate material for sequencing. PCR-free techniques are favored where feasible to eliminate biases.
3. Sequencing: Data Generation
Upon preparation of the library, the sample proceeds to sequencing. The selection of sequencing technology is contingent upon parameters like read length specifications, accuracy, and requirements for the project. Prominent sequencing platforms include:
Illumina Sequencing
-
Technology: Illumina employs sequencing by synthesis (SBS), wherein fluorescently labeled nucleotides are integrated into an elongating DNA strand, and a camera captures the signal for base identification.
-
Short Reads: Generally generates brief reads (50–300 bp) with elevated precision.
-
Applications: Suitable for various purposes including whole-genome sequencing (WGS), RNA sequencing (RNA-seq), and exome sequencing.
-
Challenges: Short reads may encounter difficulties in resolving intricate regions, particularly those characterized by structural changes or elevated GC content.
Nanopore Sequencing
-
Technology: Nanopore sequencing, developed by Oxford Nanopore, involves the translocation of DNA or RNA via a nanopore, measuring variations in ionic current to ascertain nucleotide sequences.
-
Long Reads: Able to produce substantial read lengths (up to several megabases).
-
Applications: Beneficial for addressing structural variants, repeating sections, and generating real-time data.
-
Challenges: Elevated error rates relative to Illumina, however advancements in base-calling are mitigating these errors.
PacBio Sequencing (SMRT)
-
Technology: PacBio's Single Molecule, Real-Time (SMRT) sequencing produces longer reads with elevated precision.
-
Applications: Preferred for tasks necessitating extensive readings to construct intricate genomic regions or identify structural changes.
-
Challenges: Elevated cost per base compared to Illumina.
4. Quality Control of Raw Reads
Following the generation of raw sequencing reads, quality control (QC) is essential to guarantee data integrity and dependability for subsequent studies. This procedure often involves assessing read quality, filtering poor data, and eliminating artifacts. It is imperative that the final collection of reads maintains high quality to ensure accurate and reproducible outcomes. A dedicated section will address the particulars of quality control methods and tools.
5. Data Storage and Management
Sequencing produces extensive data that requires effective management and storage.
-
Data Formats: Raw reads are preserved in FASTQ format, encompassing both sequences and quality ratings. Compressed formats such as BAM or CRAM are utilized for long-term storage.
-
Backup: Due to the magnitude of genetic data, routine backups utilizing high-capacity storage devices are required. Cloud resources or local high-performance computing storage systems are commonly utilized.
-
Data Sharing: To facilitate reproducibility and adhere to open data standards, raw sequencing data is frequently submitted to public repositories such as the Sequence Read Archive (SRA) or the European Nucleotide Archive (ENA).
The production of raw sequencing reads is fundamental to genomics and bioinformatics. Each step, from DNA/RNA extraction and library preparation to sequencing and quality control, is essential for maintaining the accuracy of downstream analyses. With the advancement of sequencing technologies, researchers can further investigate novel realms in genomics with enhanced resolution and precision. The accessibility of raw sequencing data in public repositories facilitates transparency and reproducibility of research outcomes. Researchers can readily access and authenticate the data, fostering collaboration and further progress in the domain of genetics.
-
Resource 1: Library preparation methods for next-generation sequencing: Tone down the bias .
-
Resource 2: Zverinova, S., & Guryev, V. (2022). Variant calling: Considerations, practices, and developments. Human Mutation, 43(8), 976–985. .